
Real-Time Open-Vocabulary Object Detection
CVPR 2024
For business licensing and other related inquiries, don't hesitate to contact us.
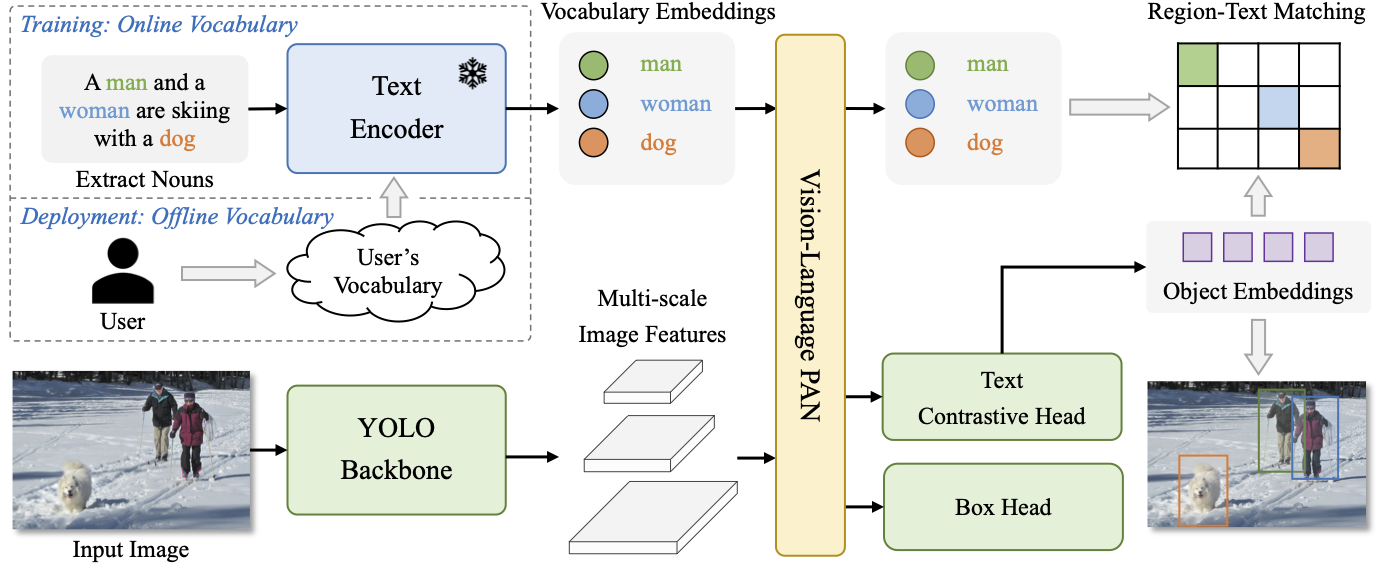
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
 YOLO-World
YOLO-World
|
|
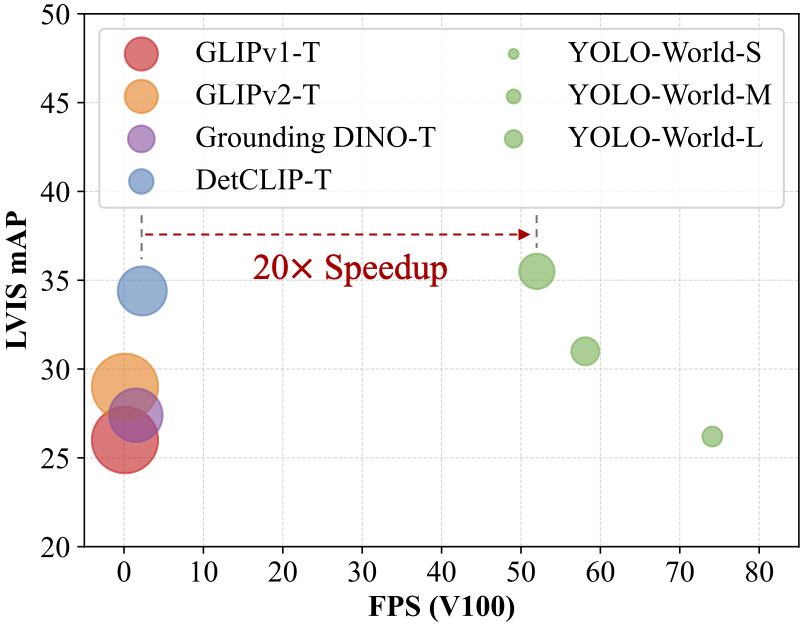
We compare the zero-shot performance on LVIS (minival) of recent open-vocabulary detectors:
| Method | Backbone | Pre-trained Data | FPS(V100) | AP | APr |
|---|---|---|---|---|---|
| GLIP-T | Swin-T | O365,GoldG | 0.12 | 24.9 | 17.7 |
| GLIP-T | Swin-T | O365,GoldG,Cap4M | 0.12 | 26.0 | 20.8 |
| GLIPv2-T | Swin-T | O365,GoldG | 0.12 | 26.9 | - |
| GLIPv2-T | Swin-T | O365,GoldG,Cap4M | 0.12 | 29.0 | - |
| GroundingDINO-T | Swin-T | O365,GoldG | 1.5 | 25.6 | 14.4 |
| GroundingDINO-T | Swin-T | O365,GoldG,Cap4M | 1.5 | 27.4 | 18.1 |
| DetCLIP-T | Swin-T | O365,GoldG | 2.3 | 34.4 | 26.9 |
| YOLO-World-S | YOLOv8-S | O365,GoldG | 74.1 | 26.2 | 19.1 |
| YOLO-World-M | YOLOv8-M | O365,GoldG | 58.1 | 31.0 | 23.8 |
| YOLO-World-L | YOLOv8-L | O365,GoldG | 52.0 | 35.0 | 27.1 |
| YOLO-World-L | YOLOv8-L | O365,GoldG,CC-250K | 52.0 | 35.4 | 27.6 |
We compare the speed and accuracy curve of pre-trained YOLO-World vesus recent open-vocabulary detectors on zero-shot LVIS evaluation:
We provide some visualization results generated by the pre-trained YOLO-World(L):



@article{cheng2024yolow,
title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
journal={arXiv preprint arXiv:},
year={2024}
}
This website is adapted from Nerfies, LLaVA, and ShareGPT4V, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.